Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

In the age of Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) has become a powerful technique to generate accurate, up-to-date, and context-aware answers by combining external knowledge with generative AI.
In this blog, we’ll walk through how to build a RAG pipeline using LangChain — starting from loading your documents (PDF, text, web), splitting them, embedding them into vectors, storing them in a vector database, and finally using them in a complete retrieval-based chatbot or QA system.

RAG (Retrieval-Augmented Generation) is a technique that combines information retrieval with text generation. Instead of relying solely on a language model’s internal memory, RAG fetches relevant documents from an external knowledge base (using embeddings and vector databases) and provides them as context for the LLM to generate informed responses.
In a RAG (Retrieval-Augmented Generation) pipeline, the first step is ingesting raw data. LangChain simplifies this through Document Loaders, which help load data from multiple file types and sources — whether it’s a .txt file, a .pdf, a website, or even structured formats like CSV or JSON.
Document loaders convert unstructured or semi-structured data into Document objects, which are later processed and used for retrieval by the LLM.
A Document Loader is a class in LangChain that reads content from a source and returns it as a list of Document objects. Each Document typically includes:
page_content: the main content (text)metadata: useful metadata such as source path, page number, or URLTextLoader – Load a Simple Text File
from langchain_community.document_loaders import TextLoader
loader = TextLoader("example.txt")
documents = loader.load()
PyPDFLoader – Loads content from PDF files, split page by page.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("document.pdf")
documents = loader.load()
WebBaseLoader – Loads data from web pages by scraping the content.
from langchain_community.document_loaders import WebBaseLoader
import bs4
loader=WebBaseLoader(web_paths=("https://python.langchain.com/docs/integrations/document_loaders/",),)
docs=loader.load()
Explore the full list of loaders here:
https://python.langchain.com/docs/integrations/document_loaders
Once you’ve loaded documents using loaders like TextLoaderPyPDFLoaderWebBaseLoader
Why?
👉 Because LLMs like GPT have a context length limit, and chunking ensures:
A Text Splitter takes in long documents and splits them into smaller chunks, each ideally representing a self-contained semantic unit of text. Each chunk can overlap with others, ensuring contextual continuity.
The most robust and commonly used splitter. It tries multiple strategies recursively to split at natural boundaries — like paragraphs or sentences — before falling back to characters.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap = 100)
final_documents = text_splitter.split_documents(docs)
Splits text into chunks by character count, without considering sentence or paragraph boundaries.
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator="\n",
chunk_size=300,
chunk_overlap=30
)
chunks = splitter.split_documents(all_docs)
chunk_size – Maximum size of each chunk (in characters or tokens
chunk_overlap – Overlap between chunks to maintain context
LangChain provides a wide range of text splitters for specific file types and formats — Markdown, CSV, HTML, JSON, and more.
https://python.langchain.com/docs/concepts/text_splitters
Once your documents are split into meaningful chunks, the next step in building a RAG pipeline is to convert those text chunks into numerical representations, called embeddings. These embeddings are stored in a vector database and used to find the most relevant chunks when a user asks a question.
Embeddings are high-dimensional vector representations of text that capture semantic meaning. Similar texts have similar embeddings, which allows us to perform semantic search — a core part of RAG.
For example:
"What is AI?" and "Explain Artificial Intelligence" will have similar embeddings.
| Provider | Class | Notes |
|---|---|---|
| OpenAI | OpenAIEmbeddings | Cloud-based, powerful, easy |
| Hugging Face | HuggingFaceEmbeddings | Local models like all-MiniLM |
| Cohere | CohereEmbeddings | Cloud-based, free tier |
| Google PaLM | GooglePalmEmbeddings | For Google AI services |
| Azure | AzureOpenAIEmbeddings | Enterprise-ready |
LangChain provides a variety of embedding providers — both API-based and local.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
text="This is a tutorial on OPENAI embeddings"
query_result = embeddings.embed_query(text)
embed_query() – used for converting a user question into a vector during retrieval
len(query_result)
3072
For offline or privacy-sensitive setups, HuggingFace embeddings are ideal.
from langchain_huggingface import HuggingFaceEmbeddings
embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
query_embedding = embeddings.embed_query("hello AI")You can refer different embeddings here:
https://python.langchain.com/docs/integrations/text_embedding
After converting your text chunks into embeddings (vectors), the next step in the RAG pipeline is to store them in a vector database. This helps you search and retrieve the most relevant chunks based on a user’s query.
A vector database stores high-dimensional vectors (like your embedded text) and helps you find the most similar ones quickly using similarity search (e.g., cosine similarity).
Think of it like Google Search, but instead of matching keywords, it matches meanings of texts.
| Vector DB | Type | Description |
|---|---|---|
| FAISS | Local | Fast and easy, good for testing and small apps |
| Pinecone | Cloud | Scalable and production-ready |
| Chroma | Local | Lightweight and simple |
| Weaviate | Cloud/Local | Offers metadata filtering |
| Qdrant | Open-source | Supports filtering and hybrid search |
vector_store=FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
vector_store.add_texts(["AI is future","AI is powerful","Dogs are cute"])
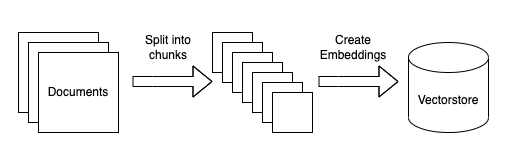
Once your document chunks are stored as embeddings in a vector database, you can use similarity search to find the most relevant information based on a user’s question.
Similarity Search compares the user query embedding with the document embeddings stored in your vector database and returns the chunks that are most similar in meaning.
Instead of exact word matches (like traditional search), it finds semantically related content.
vector_store=FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
vector_store.add_texts(["AI is future","AI is powerful","Dogs are cute"])
results = vector_store.similarity_search("Tell me about AI", k=2)We get output as
[Document(id='ca455999-8dbe-4065-9052-82b65ef06c5b', metadata={}, page_content='AI is powerful'),
Document(id='e35c7715-e0dd-4280-adab-4cc0f83db33c', metadata={}, page_content='AI is future'),
Document(id='48092ecf-2299-43da-a160-404eac2e51d8', metadata={}, page_content='Dogs are cute')]the parameter k stands for:
The number of most similar documents (chunks) to retrieve from the vector database.
Retrieval-Augmented Generation (RAG) is a powerful approach to enhance the output of large language models by combining them with external knowledge sources. In this guide, we’ll show how to build a simple RAG pipeline using a PDF file, LangChain’s tools, OpenAI embeddings, and FAISS as the vector database.
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
import faiss
from langchain_community.vectorstores import FAISS
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_huggingface import HuggingFaceEmbeddings
FILE_PATH = r"C:\AgenticAI\2-Langchain_Basics\2.4-Vector-db\llama2.pdf"
loader = PyPDFLoader(FILE_PATH)
pages = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
split_docx = splitter.split_documents(pages)
embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
index = faiss.IndexFlatIP(384)
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
vector_store.add_documents(documents=split_docx)
retriver = vector_store.as_retriever(
search_kwargs={"k": 10}
)
retriver.invoke("what is llma model")
In this RAG pipeline, we begin by using PyPDFLoader from langchain_community.document_loaders to load the contents of a PDF file — in this case, llama2.pdf. This loader reads each page and converts it into structured Document objects, making the text ready for downstream processing.
Once loaded, we use RecursiveCharacterTextSplitter to chunk the document content into manageable pieces. Here, each chunk is limited to 500 characters with a 50-character overlap. This overlap ensures that contextual continuity is maintained between chunks, which is especially important in semantic search and retrieval-based tasks.
After splitting, we initialize HuggingFaceEmbeddings using the lightweight and efficient "all-MiniLM-L6-v2" model. This step transforms each document chunk into high-dimensional vectors that capture semantic meaning — critical for finding similar chunks later. These embeddings are fully open-source, ideal for developers seeking alternatives to proprietary APIs.
To store and search these vectors efficiently, we use FAISS (faiss.IndexFlatIP), a fast and scalable vector similarity library. The FAISS vector store is wrapped using LangChain’s FAISS class, where we also configure an InMemoryDocstore to map vector IDs to the original documents.
Once set up, we call add_documents() to embed and insert the chunks into the FAISS index. Finally, we convert the vector store into a retriever using .as_retriever() and query it with "what is llma model". The retriever fetches the top 10 most semantically similar chunks using inner product similarity, which can then be fed to a language model for answer generation.
Building a Retrieval-Augmented Generation (RAG) system using LangChain, FAISS, and Hugging Face embeddings offers a powerful and flexible way to unlock insights from your own documents like PDFs. By loading documents with PyPDFLoader, splitting text into meaningful chunks using RecursiveCharacterTextSplitter, and converting those chunks into semantic vectors with Hugging Face’s all-MiniLM-L6-v2 model, you create a robust foundation for efficient and accurate semantic search.
FAISS enables lightning-fast similarity searches over these vectors, making it easy to retrieve the most relevant information for any query. This approach is especially valuable for developing intelligent chatbots, document search engines, or knowledge assistants that require deep understanding grounded in your data.
With fully open-source tools, this pipeline is customizable and scalable for a wide range of applications. If you want to build AI systems that combine the strengths of retrieval and generation, leveraging LangChain with Hugging Face embeddings and FAISS is an excellent choice.